1. 安装 JDK
1.1 检查 JDK 版本
检查 Mac 上是否已经安装了 jdk,在终端上执行命令
java -version
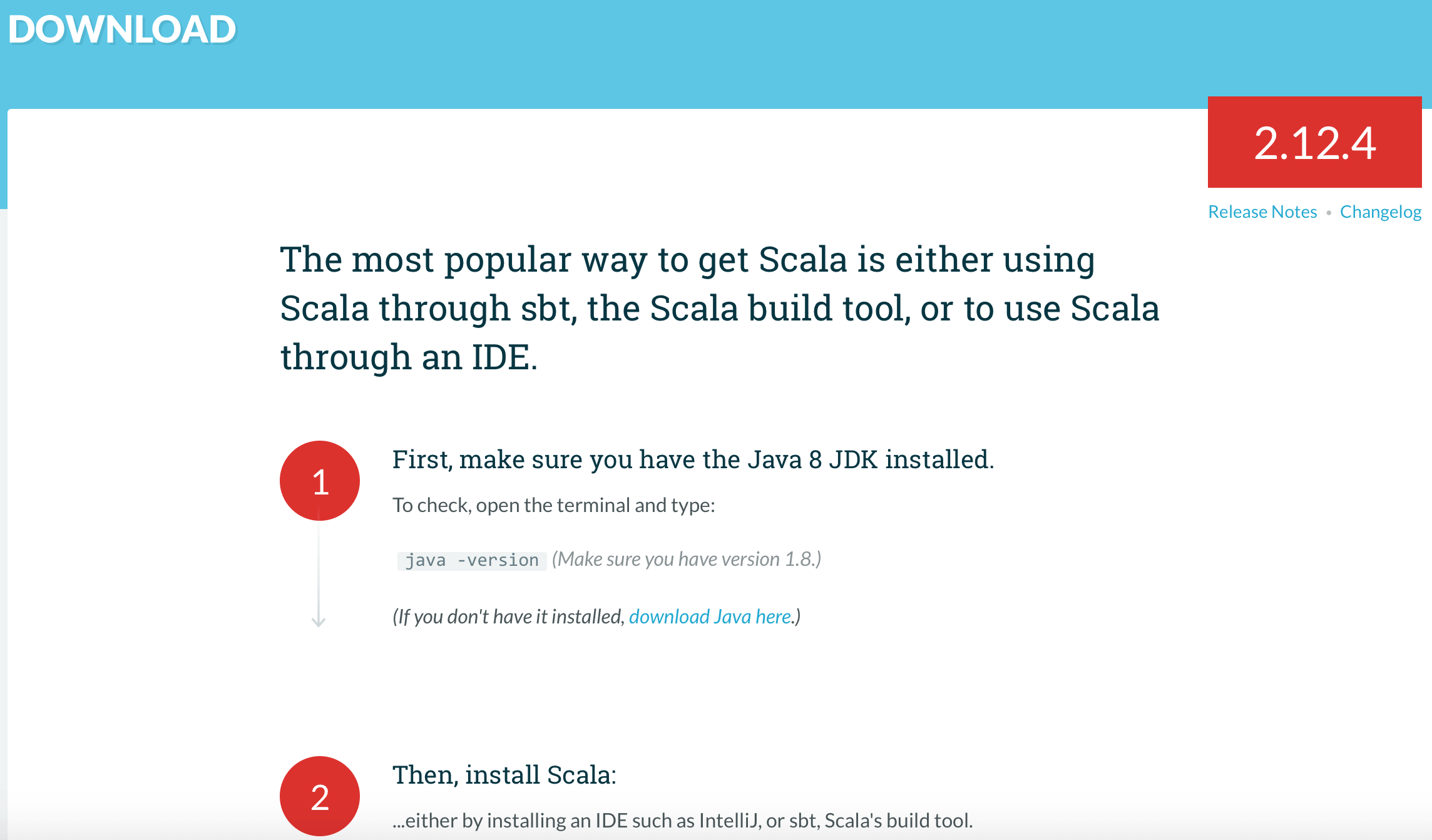
Spark 是使用 scala 语言开发的,如果要使用 Scala,就需要安装与之对应的 jdk 版本,Scala 的下载地址:http://www.scala-lang.org/download/。下载地址页面明确说明了要使用 Scala 就必须要求 java version 为 1.8 以上,也就是 Java 8 JDK 以上版本。

1.2 安装 JDK
如果 Mac 上没有安装 jdk,jdk 的下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html,选择 Mac 版本的 jdk 下载,下载后安装。
安装完成后,在终端执行命令如下命令查看是否成功安装
java -version
2. 安装 Spark
2.1 下载 Spark
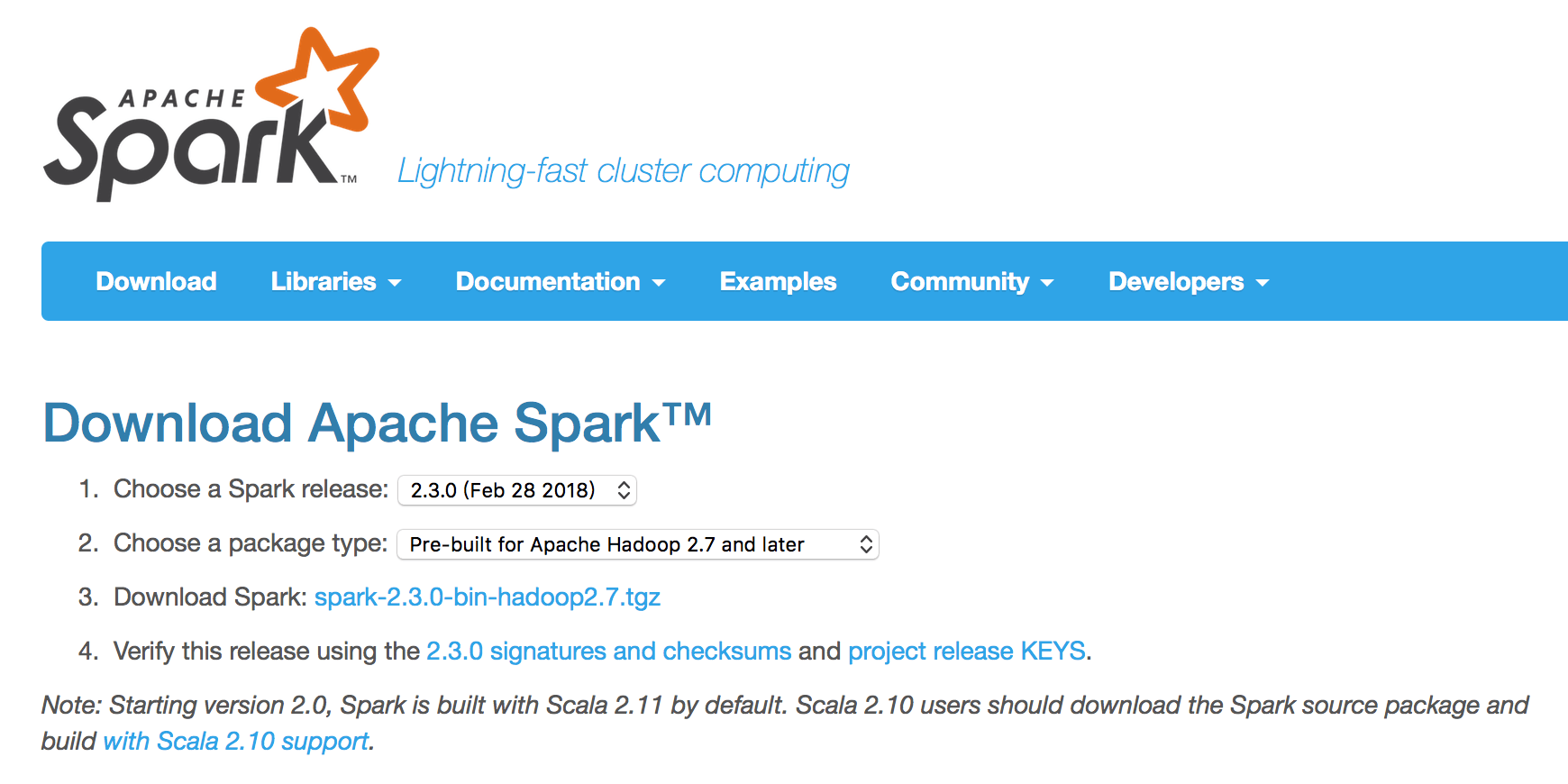
Spark 压缩包的下载地址为:http://spark.apache.org/downloads.html,选择合适的版本安装。我选择的是 spark-2.3.0-bin-hadoop2.7.tgz 版本。
2.2 解压 Spark
将 spark-2.3.0-bin-hadoop2.7.tgz 解压到你的某个文件目录下。我的文件目录结构是

2.3 运行 Spark
进入 Spark 所在的目录下,执行 Scala 脚本启动 Spark
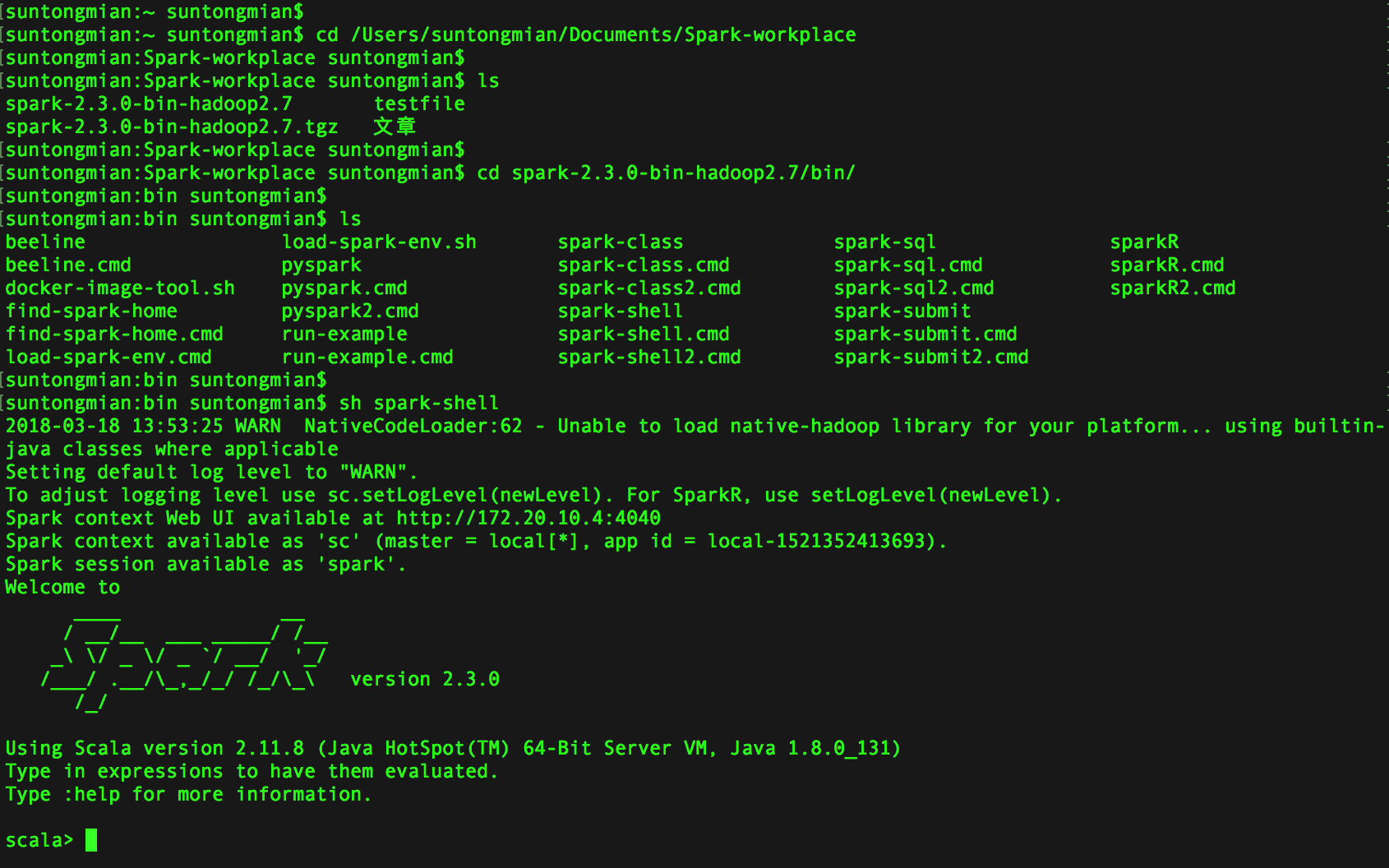
根据终端的显示结果,在 Chrome 浏览器上访问 http://172.20.10.4:4040,会出现 Spark 的 web 页面,可以点击 Jobs,Stages,Storage,Environment,Executors 等菜单项看看 Spark 都运行了哪些服务,更加直观地了解 Spark 是个什么样的东西。
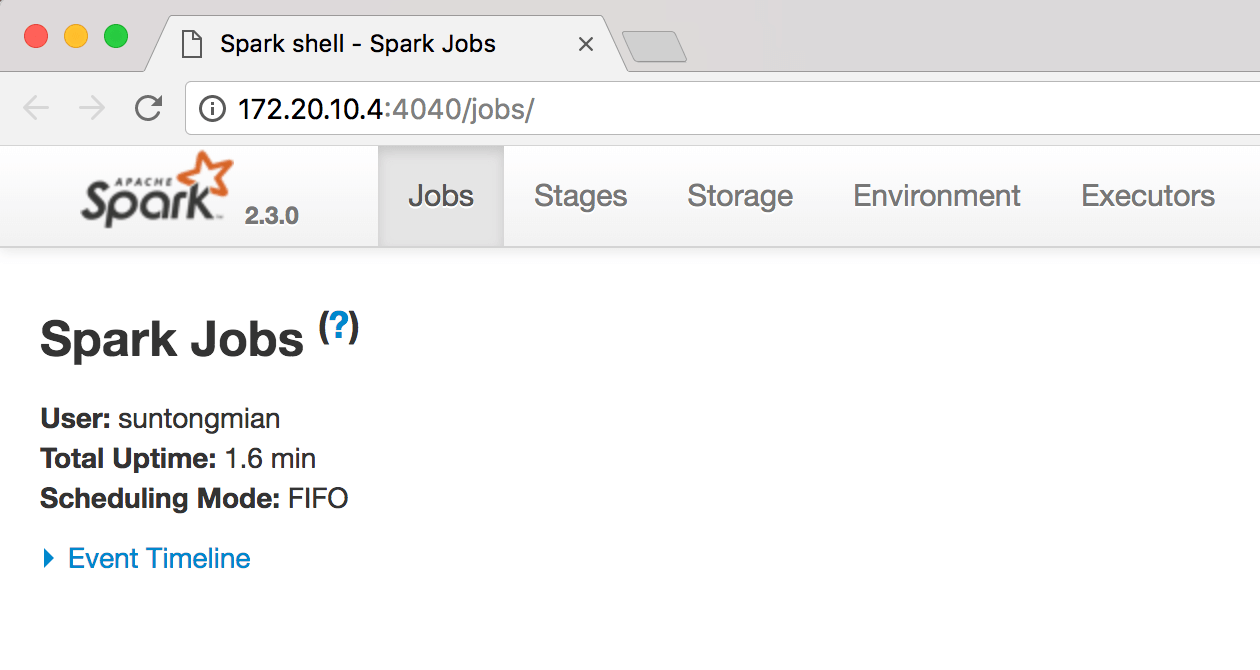
启动了 Spark,也在浏览器上看到了其可视化界面,接下来就来个例子试试 Spark。
在 spark-2.3.0-bin-hadoop2.7 所在的目录下,新建一个 testfile 目录,testfile 目录下新建一个文件 helloSpark,并写上简单几行文字。
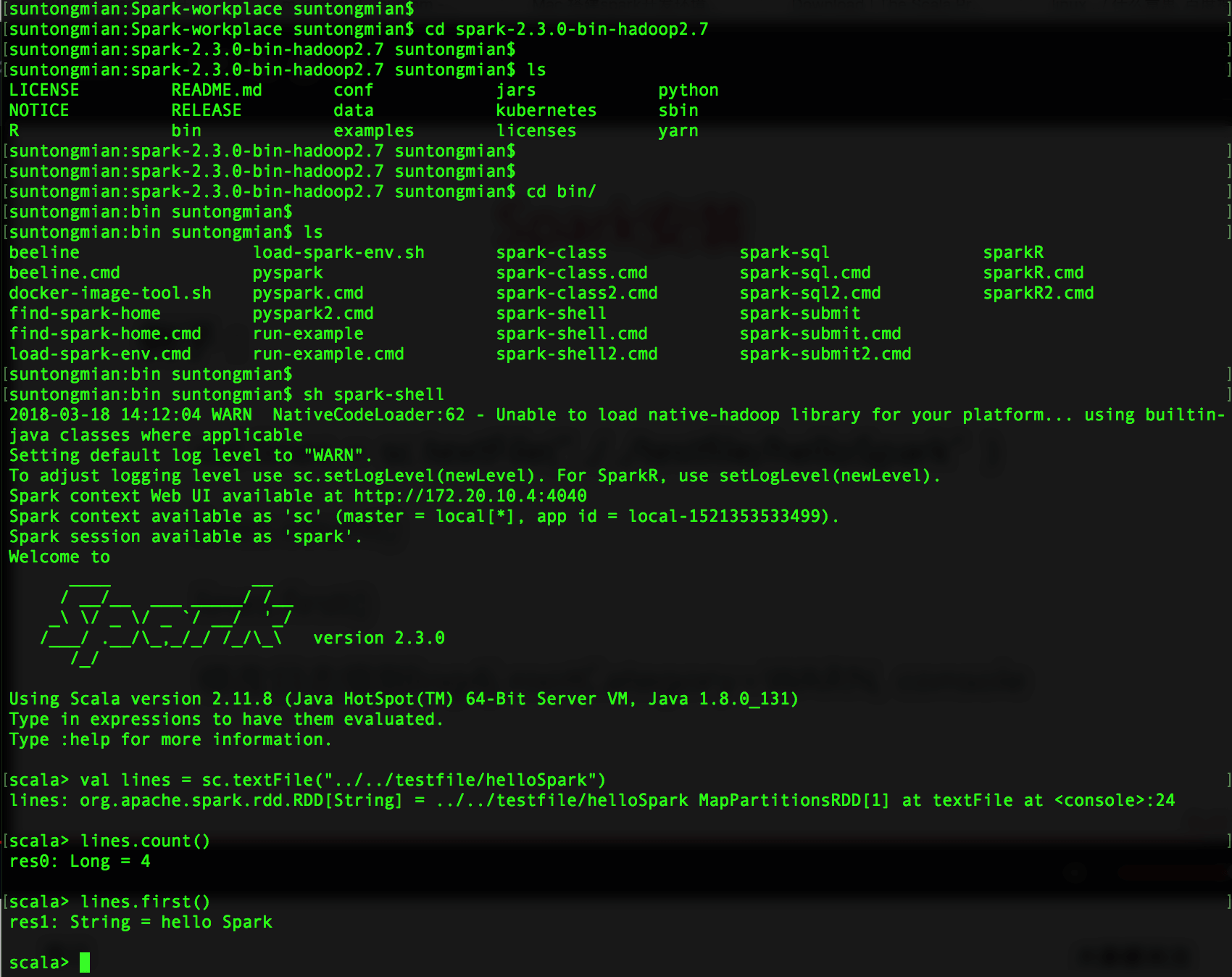
在 bin 目录下执行脚本 spark-shell,并使用 Scala 统计 helloSpark 文件中的函数、文件中第一行的内容
helloSpark 文件和 spark-shell 脚本所在的目录如下图
注意:可能有些朋友不清楚 val lines = sc.textFile("../../testfile/helloSpark") 中 ../ 的意思,../ 表示上一层目录,../../ 表示上上层目录。
到此,Spark 的简单试用结束了。想了解 sc.textFile,大家自行 google 或 baidu。
对于初学者来说,有相应的视频配合的话,会对 Spark 的安装有更新直观的视觉体验。给大家推荐下视频:Spark 从零开始-Spark 安装